
Stanford University
(*Equal Contribution)
We study inferring 3D object-centric scene representations from a single image. While recent methods have shown potential in unsupervised 3D object discovery, they are limited in generalizing to unseen spatial configurations. This limitation stems from the lack of translation invariance in their 3D object representations. Previous 3D object discovery methods entangle objects' intrinsic attributes like shape and appearance with their 3D locations. This entanglement hinders learning generalizable 3D object representations. To tackle this bottleneck, we propose the unsupervised discovery of Object-Centric neural Fields (uOCF), which integrates translation invariance into the object representation. To allow learning object-centric representations from limited real-world images, we further introduce an object prior learning method that transfers object-centric prior knowledge from a synthetic dataset. To evaluate our approach, we collect four new datasets, including two real kitchen environments. Extensive experiments show that our approach significantly improves generalization and sample efficiency, and enables unsupervised 3D object discovery in real scenes. Notably, uOCF demonstrates zero-shot generalization to unseen objects from a single real image.
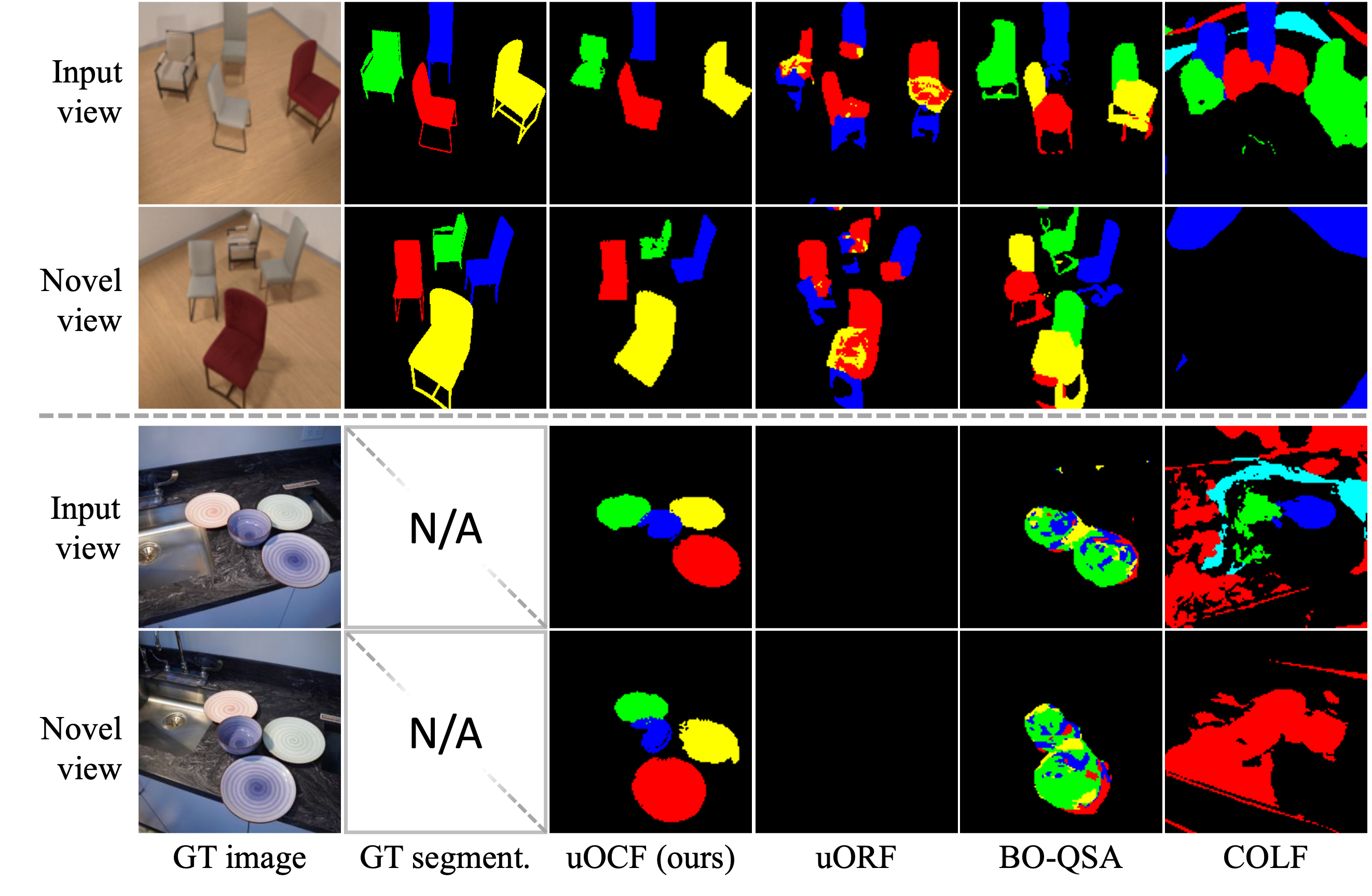
Given a real image (the first frame) with visually-rich objects, uOCF infers the factorized 3D object-centric scene representations, enabling reconstruction and manipulation from arbitrary novel views.



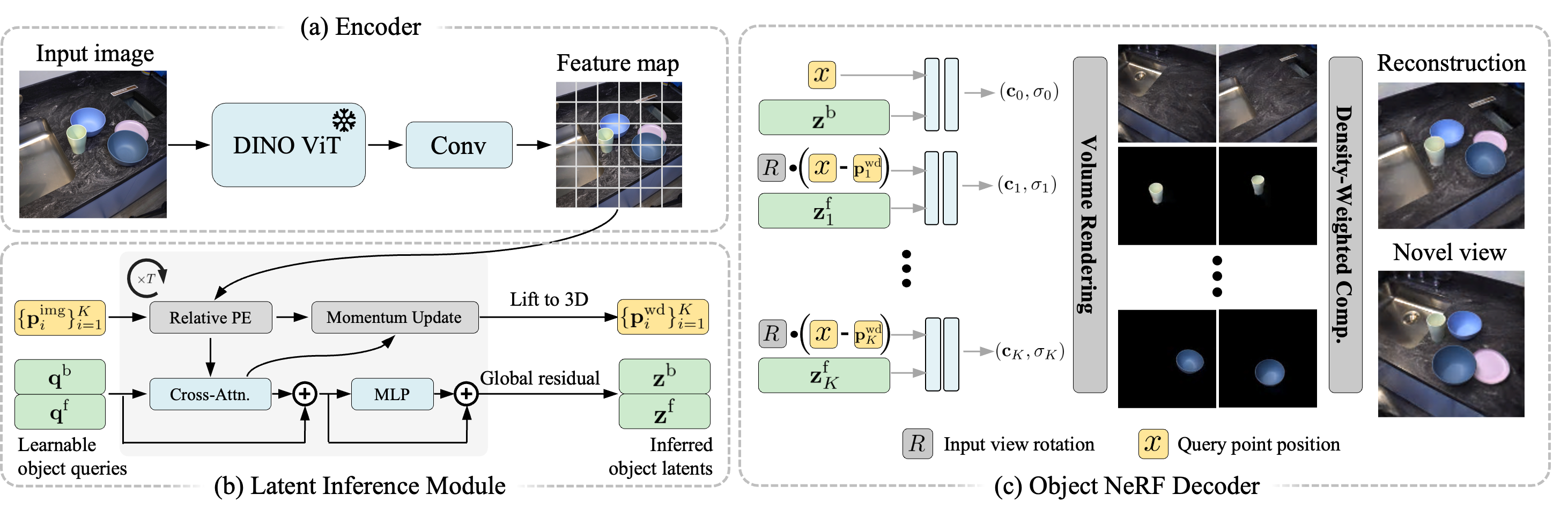
Our model consists of an encoder, a latent inference module, and a decoder. The encoder extracts features from the input image. The latent inference module infers the objects' latent representations and positions in the underlying 3D scene from the obtained feature map. Finally, the object NeRF decoder decodes the latent representations and positions into the object-centric neural fields and composes them to reconstruct the scene.
We introduce object-centric prior learning to address the inherent difficulty caused by the ambiguities in complex compositional scenes. The main idea is to learn object priors (e.g., physical coherence) from simple scenes (e.g., scenes with a single synthetic object), then leverage the obtained priors to learn from more complex scenes that could potentially have very different scene geometry and spatial layout. An illustration is shown below.

@article{uOCF,
title={Unsupervised Discovery of Object-Centric Neural Fields},
author={Luo, Rundong and Yu, Hong-Xing and Wu, Jiajun},
journal={arXiv},
year={2024},
}
If you have any questions, please feel free to contact us: